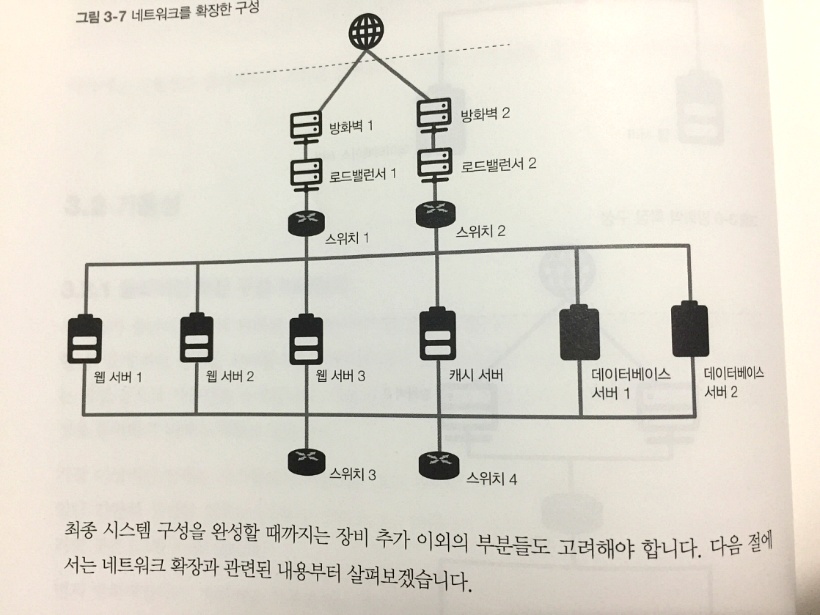
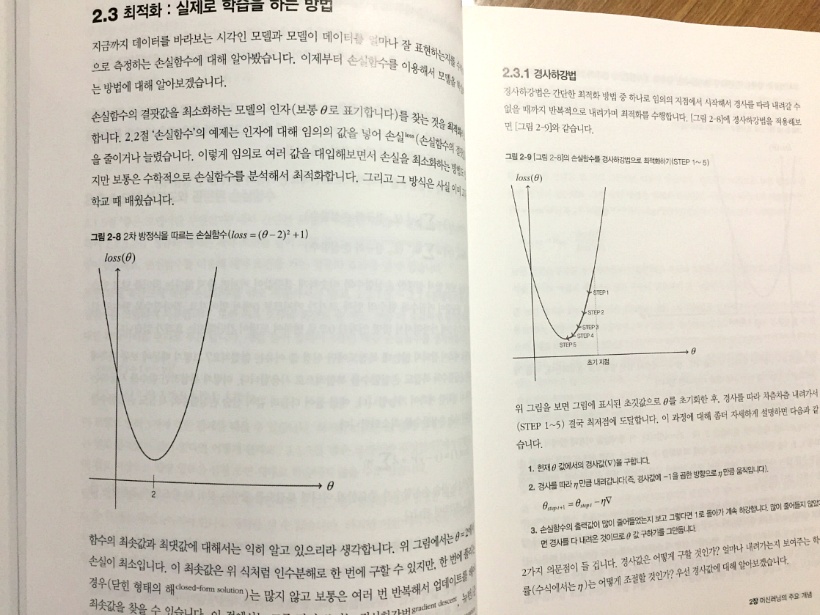
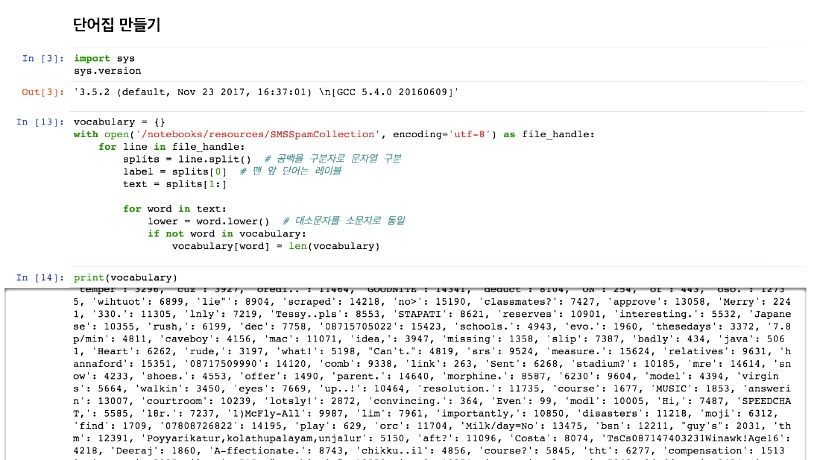
현재 프로덕션 환경에서 Amazon Elasticsearch Service를 사용 중이었는데 물리적인 부분을 AWS에서 관리해주는 장점도 있는 반면 비용적인 부분이나 제약사항들 때문에 불편한 부분들이 있었다. 그래서 EC2 인스턴스에 직접 구성해볼까 고민하던 차에 이번에 Elastic Stack이 버전업이 된 것을 계기로 이전을 해보기로 결심했다. 가장 문제되는 부분이 현재 쌓인 데이터를 어떻게 문제 없이 옮길까 하는 것이었는데 현재 몽고디비에 이중으로 데이터를 보관하고 있었기 때문에 몽고디비에 쌓인 데이터를 bulk insert를 사용하여 재 색인을 하려고 하였는데 시간이 엄청나게 소요되었다. 그래서 스냅샷 기능을 활용해보기로 하였고, 결과적으로 매우 빠르게 데이터를 옮길 수 있었다.
Amazon Elasticsearch에서 snapshot을 생성하기 위해서는 먼저 Elasticsearch 서비스와 S3에 접근 할 수 있는 IAM Role이 필요하다. 역할(Role)을 생성할 때 아래의 페이지에서 신뢰할 수 있는 유형의 개체를 선택해야 하는데 현재 Elasticsearch가 존재하지 않기 때문에 EC2를 선택하여 생성하도록 한다.
![]()
그리고나서 정책(Policy) 생성 버튼을 클릭하고 아래 JSON 문자열을 직접 입력한다. 여기서는 버켓 이름을 hive-es-index-backups로 생성했다.
{
"Version":"2012-10-17",
"Statement":[
{
"Action":[
"s3:ListBucket"
],
"Effect":"Allow",
"Resource":[
"arn:aws:s3:::hive-es-index-backups"
]
},
{
"Action":[
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"iam:PassRole"
],
"Effect":"Allow",
"Resource":[
"arn:aws:s3:::hive-es-index-backups/*"
]
}
]
}생성이 완료되면 역할 목록에서 방금 생성한 역할을 선택한 후 신뢰 관계 편집을 선택하여 ec2로 설정되어 있는 부분을 아래와 같이 es로 변경한다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "es.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}IAM 설정이 완료되었으므로 이제는 snapshot을 어떠한 방식으로 저장할지를 elasticsearch 쪽에 지정하는 snapshot repository 생성 절차가 필요하다. 이를 위해 먼저 repository를 생성하는 파이썬 스크립트를 작성한 후 수행한다. (IAM 설정과 파이썬 스크립트는 AWS 백서에 잘 나와있다.)
from boto.connection import AWSAuthConnection
classESConnection(AWSAuthConnection):
def__init__(self, region, **kwargs):
super(ESConnection, self).__init__(**kwargs)
self._set_auth_region_name(region)
self._set_auth_service_name("es")
def_required_auth_capability(self):
return ['hmac-v4']
if__name__=="__main__":
client = ESConnection(
region='ap-northeast-2',
host='search-xxx.ap-northeast-2.es.amazonaws.com',
aws_access_key_id='<ACCESS_KEY>',
aws_secret_access_key='<SECRET_KEY>', is_secure=False)
print('Registering Snapshot Repository')
resp = client.make_request(method='POST',
path='/_snapshot/hive-es-backup',
data='{"type": "s3","settings": { "bucket": "hive-es-index-backups","region": "ap-northeast-2","role_arn": "arn:aws:iam::<ACCOUNTID>:role/ESSnapshotRole"}}')
body = resp.read()
print(body)client.make_request 함수의 인자로 repository명과 repository에 대한 설정을 지정한 후 요청하면 해당 내용으로 elasticsearch에 repository가 생성된다.
kibana의 Dev Tools를 사용하여 아래 명령을 수행해보자.
GET _snapshot?pretty
그러면 아래와 같이 생성된 repository정보를 확인할 수 있다.
{
"cs-automated": {
"type": "s3"
},
"hive-es-backup": {
"type": "s3",
"settings": {
"bucket": "hive-es-index-backups",
"region": "ap-northeast-2",
"role_arn": "arn:aws:iam::<ACCOUNTID>:role/<ROLE_NAME>"
}
}
}
이제 실제로 스냅샷을 생성해야하는데 여기서는 1월 1일에 생성된 인덱스인 hive_live_2018_01_01 인덱스를 색인하도록 한다. 완료될 때까지 기다리려고 wait_for_completion 설정을 true로 지정하였는데 이것도 내부적으로 timeout 시간이 있는지 기다리가다 Fail 오류가 발생한다.
PUT _snapshot/hive-es-backup/hive_live_2018_01_01?wait_for_completion=true
{
"indices": "hive_live_2018_01_01",
"ignore_unavailable": true,
"include_global_state": false
}스냅샷이 정상적으로 되었는지 확인하려면 아래 명령을 수행한다. (특정 스냅샷만 보려는 경우 _all 부분을 snapshot 명으로 입력한다.)
GET _snapshot/hive-es-backup/_all?pretty
하지만 snapshot 상태 정보를 확인(GET /_snapshot/hive-es-backup/hive_live_2018_01_01)해보면 IN_PROGRESS 상태인 걸보니 내부적으로는 진행 중인 듯 하다.
{
"snapshots": [
{
"snapshot": "hive_live_2018_01_01",
"uuid": "_ecORIa8RteCruw54pDzCA",
"version_id": 5050299,
"version": "5.5.2",
"indices": [
"hive_live_2018_01_01"
],
"state": "IN_PROGRESS",
"start_time": "2018-01-18T01:48:39.244Z",
"start_time_in_millis": 1516240119244,
"end_time": "1970-01-01T00:00:00.000Z",
"end_time_in_millis": 0,
"duration_in_millis": -1516240119244,
"failures": [],
"shards": {
"total": 0,
"failed": 0,
"successful": 0
}
}
]
}잠시 기다린 후 다시 상태 정보를 확인해보면 아래와 같이 SUCCESS 상태로 전환된 것을 확인할 수 있다.
{
"snapshots": [
{
"snapshot": "hive_live_2018_01_01",
"uuid": "_ecORIa8RteCruw54pDzCA",
"version_id": 5050299,
"version": "5.5.2",
"indices": [
"hive_live_2018_01_01"
],
"state": "SUCCESS",
"start_time": "2018-01-18T01:48:39.244Z",
"start_time_in_millis": 1516240119244,
"end_time": "2018-01-18T01:53:11.247Z",
"end_time_in_millis": 1516240391247,
"duration_in_millis": 272003,
"failures": [],
"shards": {
"total": 5,
"failed": 0,
"successful": 5
}
}
]
}완료된 스냅샷을 로컬 엘라스틱서치에서 복원하기 위해서는 로컬 엘라스틱서치에도 마찬가지로 S3로 snapshot을 생성(이 때는 readonly로 설정하는 것이 좋음) 해야하는데 S3에 접근하기 위해서는 repository-s3 플러그인이 설치되어 있어야 한다.
$ ./elasticsearch-plugin install repository-s3
다음으로 AWS 서비스에 접근하기 위한 access key와 secret key에 대한 설정이 필요한데 이는 elasticsearch-keystore를 통해 등록이 가능하다. list 명령을 통해 keystore가 존재하는지 확인해보고, 존재하지 않을 경우에는 생성한다.
$ bin/elasticsearch-keystore list
ERROR: Elasticsearch keystore not found. Use 'create'command to create one.
$ bin/elasticsearch-keystore create
Created elasticsearch keystore in /home/ubuntu/programs/elasticsearch-6.1.2/config
access/secret키를 아래 명령을 통해 입력하도록 한다.
$ ./elasticsearch-keystore add s3.client.default.access_key
$ ./elasticsearch-keystore add s3.client.default.secret_key
이제 로컬 키바나를 통해(curl 명령을 사용해도 되지만 편의상 키바나를 사용했다.) elasticsearch로 동일한 repository(S3 버켓)를 생성하도록 한다.
PUT _snapshot/hive-es-backup
{
"type": "s3",
"settings": {
"bucket": "hive-es-index-backups",
"region": "ap-northeast-2"
}
}이제 S3에 저장된 스냅샷을 아래 명령을 통해 복원해보도록 하자.
POST /_snapshot/hive-es-backup/hive_live_2018_01_01/_restore
{
"indices": "hive_live_2018_01_01"
}그러면 순식간에 응답을 받게되는데 복원이 끝난 것을 의미하지는 않기 때문에 인덱스 상태를 확인하며 정상적으로 색인이 될 때까지 기다려야 한다. 아래 명령을 수행해보면 현재 인덱스의 상태를 확인할 수 있다.
GET /_cat/indices?v&s=index
restore 시에는 인덱스 설정이 레플리카 수는 1개, flush 주기는 1초 등 기본 값으로 설정이 되어있다. 이를 아래와 같이 변경하여 색인 성능을 높일 수도 있다.
POST /_snapshot/hive-es-backup/hive_live_2018_01_01/_restore
{
"indices": "hive_live_2018_01_01",
"index_settings": {
"index.number_of_replicas": 0,
"index.refresh_interval": -1
}
}결과를 확인해보면 복원을 수행한 직후에는 아래와 같이 document 수 조차도 계산되지 않고 인덱스만 생성되어 있고, 정상적으로 색인이 되어있는 .kibana는 health 상태가 green인 것과 달리 방금 복원을 요청했던 hive_live_2018_01_01 인덱스의 health 상태가 yellow인 것을 확인할 수가 있다.
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open hive_live_2018_01_17 B3tGrOPJRt2PaTp65g66-A 5 1
잠시 시간이 지난 후에는 document 수와 용량은 확인되지만 아직까지는 health 상태가 yellow이다.
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana SFYFvaq3RrmyjcJ1pipBYw 1 1 2 0 156.4kb 78.2kb
yellow open hive_live_2018_01_01 uLbBcPPrRoOxqWi-lgebag 5 1 4169704 0 6.7gb 6.7gb
green이 될 때까지 기다리면 복원이 완료된 것이다. 이 때 스냅샷을 생성한 엘라스틱서치의 document 개수와 복원한 엘라스틱서치의 document 개수를 꼭 확인해보도록 하자.